60 KiB
+++ title = "Decentralized forge: distributing the means of digital production" date = 2021-01-07 +++
This article began as a draft in february 2020, which i revised because the Free Software Foundation is looking for feedback on their high-priority projects list.
Our world is increasingly controled by software. From medical equipment to political repression to interpersonal relationships, software is everywhere, shaping our lives. As the luddites did centuries ago, we're evaluating whether new technologies empower us or on the contrary reinforce existing systems of social control.
This question is often phrased through a software freedom perspective: am i free to study the program, modify it according to my needs and distribute original or modified copies of it? However, individual programs cannot be studied out of their broader context. Just like the human and ecological impact of a product cannot be imagined by looking at the product itself, so does a binary program tell us little about its conditions of production and envisioned goals.
A forge is another name for a software development platform. The past two decades have been rich in progress on forging ecosystems, empowering many projects to integrate tests, builds, fuzzing, or deployments as part of their development pipeline. However, there is a growing privatisation of the means of digital production: Github, in particular, is centralizing a lot of forging activities on its closed platform.
In this article, I argue decentralized forging is a key issue for the future of free software and non-profit software development that empowers users. It will cover:
- Github considered harmful (what Github did well, and why they are now a problem)
- git is decentralized, but the workflows aren't standardized (why email forging is not yet practical for everyone)
- Selfhosted walled gardens are not a solution (how selfhosted forges can limit cooperation)
- Centralized and decentralized trust (how to discover and authenticate content in a decentralized setting)
- Popular self-defense against malicious activities (what are the threats, and how to empower our communities against them)
- Existing decentralized forging solutions (both federated and peer-to-peer)
- With interoperability, please
- Code signing and nomadic identity
- Social recovery and backup mechanisms
- and a short conclusion
This article assumes you are somewhat familiar with software development, decentralized version control system (DVCS) such as git, cooperative forging (collaboration between mutliple users), and some notions of asymetric cryptography (public/private keys, signatures).
Glossary
- forge: a program facilitating cooperation on a project
- DVCS: a version control system such as git
- repository: a folder, containing versioning metadata, to represent several versions of the same project
- source: the contents of the repository (excluding versioning metadata)
- commit: a specific version of a repository, in which the commit name is the checksum of all file contents for this version of the repository
- branch: a user-friendly name pointing to a specific commit, which can be updated to point to newer commits (this is what happens when an update is pushed)
- patch: a proposal to change content from the repository, that can be understood by humans and by machines (typically, a diff), also known as a pull request or merge request (though slightly different)
- issue: a comment/discussion about the project, which is usually not contained within the repository itself (also called a ticket or a bug)
- contributors: people cooperating on a project by submitting issues and patches
- maintainers: contributors with permission to push updates to the repository (validate patches)
Github considered harmful
More and more, software developers and other digital producers are turning to Github to host their project and handle cooperation across users, groups and projects. Github is a web interface for git. From this web interface, you can browse the source of the project, submit/triage issues, and propose/review patches. While Github internals rely on git, Github does more than git itself. Notably, Github enables to define fine-grained permissions for different users/groups.
Github is what we call a web forge, that is a software suite that makes cooperation easier. It was inspired by many others that came before, like Sourceforge and Launchpad. What's different about Github, compared to previous forges, is the emphasis on user experience. While Sourceforge is great for those of us familiar with DAGs and git vocabulary (refs, HEAD, branches), Github was conceived from the beginning to be more friendly to newcomers. Using Github to produce software still requires git knowledge, but submitting a ticket (to report a bug) is accessible to anyone familiar with a web interface.
To illustrate their difference, we can look at how different forges treat the README file. From Inkscape's Launchpad project, it takes me one click to reach the list of files (sometimes called tree), and yet another click to open the README. In contrast, zola's project page on Github instantly displays the list of files, as well as the complete README.
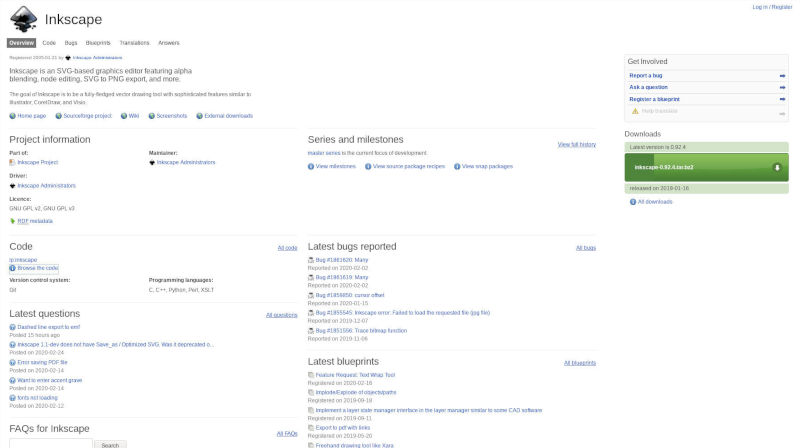
Every project is architectured differently. That's why displaying a list of branches or the latest commits on the project page brings limited value: the people who need this information likely know how to retrieve it from the git command-line (git branch or git log). README files, however, were created precisely to introduce newcomers to your project. Whether your README file is intended for novice users or people from a specific background is up to you, but Github does not stand in the way.
But not all is so bright with Github. First and foremost, Github is a private company trying to make money on other people's work. They are more than happy to use free-software projects to build their platform, but always refused to publish their own sourcecode. Such hypocrisy has long been denounced by the Free Software Foundation, which in its ethical forging evaluation gave Github the worst note possible (criteria).
Like Facebook and Google, and other centralized platforms, Github also has a reputation for banning users from the platform with little/slow recourse. Some take to forums and social media platform to get the attention of the giant in the hope of getting their account restored. That's what happened for instance when Github decided to ban all users from Iran, Crimea and Syria: users organized massive petitions, but were left powerless in the end.
Github has also been involved in very political questionable decisions. If your program is in any way interacting with copyrighted materials (such as Popcorn Time or youtube-dl), there are chances it will be taken down at some point. This is even more true if your project displeases a colonial empire (or pretend "republic") like Spain or the United States. An application promoting Catalan independance ⁽²⁾ was removed. And so was a list of police officers (ICE) compiled from entirely public data, which was finally hosted by Wikileaks.

Github has chosen their side: they will protect the privileged against the oppressed, in an effort to safeguard their own profits. They will continue to support Palantir (surveillance company) and ICE (racist police detaining/deporting people) despite protests from their users and employees, and the only option left for us is to boycott their platform entirely.
To be fair, there are examples for which I personally agree with Github's repressive actions, like when they banned a dystopian DeepNude application encouraging hurtful stalking/harrassing behavior. My point is not that Github's positions are wrong, but rather that nobody should ever hold such power.
It is entirely understandable for a person or entity to refuse to be affiliated with certain kinds of activities. However, given Github's quasi-monopoly on software forging, banning people from Github means exiling them from many projects. Likewise, banning projects from Github disconnects them from a vast pool of potential contributors. There should never be a global button to dictate who can contribute to a project, and what kind of project they may contribute to.
git is decentralized, but the workflows aren't standardized
To oppose the ever-growing influence of Github, much of the free-software community pointed out that we simply don't need it, because git is already a decentralized system, contrary to centralized versioning systems like subversion (svn). Every contributor to a git repository has a complete copy of the project's history, can work offline, then push their changes to any remote repository (called a remote in git terminology).
This property ensures that anyone can at any time take a repository, take it elsewhere, and start their own fork (modified version). However, what is outside the repository itself cannot always so easily be migrated: tickets, submitted patches, and other contributions and discussions may each have their own procedure to export, when that is possible at all.
Historically, git was developed for the Linux kernel community, where email is the core of the cooperation workflow. Tickets and patches are submitted and commented on mailing lists. git even provides subcommands for such workflow (eg git-send-mail). This workflow is less prone to censorship than centralized forges like Github, but has other challenges.
For example, when forking a project, how to advertise your fork to the community without spamming existing contributors? Surely if the original project is dead and the mailing list doesn't exist anymore, a fork's notification email would be welcome for most people. In other cases, it may be perceived as an invading action because these contributors did not explicitely consent (opt-in) to your communication, as required by privacy regulations in many countries.
Moreover, there is no standardized protocol for managing tickets and patch submissions over email. sourcehut's todo and Debian's debbugs have very good documentation for new contributors to submit issues, but in other communities it can be hard to understand the netiquette or expected ticket format for a project, even more so when this project has been going on for a long time with an implicit internal culture.
With the email workflow, every project is left to implement their own way. That can be quite powerful for complex usecases, but unexperienced persons who just want to start a cooperative project will be left powerless. Creating a project on Github takes a few clicks. In comparison, setting up a git server, a couple mailing lists (one for bugs, one for patches), and configuring correct permissions for all that is more exhausting and error-prone, unless you use an awesome shared hosting service like sr.ht.
From a contributor's perspective, it can take some time getting used to an email workflow. In particular, receiving and applying patches from other people may require using a developer-friendly email client such as emacs, aerc or neomutt. Sending patches, on the other hand, is not complicated at all. If you want to learn, there's an amazing interactive tutorial at git-send-email.io.
We have to keep in mind forging platforms are not only used by developers, but also designers, translators, editors, and many other kinds of contributors. Many of them already struggle learning git, with its infamous inconsistencies. Achieving a full-featured newcomer-friendly email forging workflow is currently still a challenge, and this is currently a hard limit on contributions from less-technical users.
Developing interoperable standards for forging over email (such as ticket management) would help a great deal. It would enable mail clients, desktop environments and integrated development environments to (IDEs) provide familiar interfaces for all interactions we need with the forge. For example, Github's issue templates could be supported in email workflows. An open email forging standard would also make it easier for web forges (and others) to enable contributions via email, reuniting two forging ecosystems who currently rarely interact because most people are familiar with one or the other, not both.
Selfhosted walled gardens are not a solution
Over the past decade, some web forges have been developed with the goal of replicating the Github experience, but in a selfhosted environment. The most popular of those are Gitlab, Gogs and Gitea (which is a fork of Gogs).
Such modern, selfhosted webforges are very popular with bigger communities and projects who already have their own infrastructure, and avoid relying on 3rd party service providers, for reliability or security concern. Forging can be integrated into their project ecosystem, for example to manage user accounts (eg. with LDAP).
However, for hobbyists and smaller communities, these solutions are far from ideal, because they were specifically developed to replicate a centralized development environment like Github. The forge is usually shut off from the outside world, and cooperation between users is only envisioned in a local context. Two users on Codeberg may cooperate on a project, but a user from 0xacab.org may not contribute to the same project without creating an account on Codeberg.
Some people may argue this is a feature and not a bug, for three reasons:
- easier enforcement of server-wide rules, guidelines and access rules: this may be an advantage in corporate settings (or for big community projects), but doesn't apply to popular hacking usecases, where all users are treated equally, and settings are defined on a per-project basis (not server-wide)
- an account on every server is more resilient to censorship or server shutdown: while true, i would argue the issue should be tackled in more comprehensive and user-friendly ways through easier project migration and nomadic identity systems (explained later in this article)
- an account on every server isn't a problem, because there's only so many projects you contribute to: though a person may only contribute seriously and frequently to a limited number of projects, there's so many more projects we use on a daily basis and don't report bugs to, because unless the project has privacy-invading telemetrics and click-to-go bug reporting, figuring out a specific project's bug reporting guidelines can be tedious
In contrast, the bug reporting workflow as achieved by Github and mailing lists is more accessible: you use your usual account, and the interface you're used to, to submit bugs to many projects. If a project uses Mailing Lists for cooperation, you can contribute to from your usual mail client. Your bug reports and patches may be moderated before they appear publicly, but you don't have to create a new account and learn a new workflow/interface just to submit a bug report.
Creating a new account for every community and project you'd like to join is not a user-friendly approach. This antipattern was already observed in a different area, with selfhosted social networks: Elgg could never replace Facebook entirely, nor could Postmill/Lobsters replace Reddit, because participation was restricted to a local community. In some cases it's feature: a family's private social network should not connect to the outside world, and a focused and friendly community like raddle.me or lobsters may wish to preserve itself from nazi trolls.
But in many cases, not being able to federate across instances (and communities) is a bug. Selfhosted centralized services tailor to the niche usecases, not because they're too different from Facebook/Reddit, but because they're technically so similar to them. Instead of dealing with a gigantic walled garden (Github), or a wild jungle (mailing lists), we now end up with a collection of tiny closed gardens. The barrier to entry to those gardens is low: you just have to introduce yourself to the frontdoor and define a password. But this barrier to entry, however low it is, is already too high.
I suspect that for smaller volunteer-run projects, the ratio of bug reporters to code committers is much higher on Github and development mailing lists than it is on smaller, selfhosted forges. If you think that's a bad thing, try shifting your reasoning: if only people familiar with programming are reporting bugs, and your project is not only aimed at developers, it means most of your users are either taking bugs for granted, or abandoning your project entirely.
Centralized and decentralized trust
When we're fetching information about a project, how to ensure it is correct? In traditional centralized and federated systems, we rely on location-addressed sources of trust. We define where to find reliable information about a project (such as a git remote). To ensure authenticity of the information, we rely on additional security layers:
- Transport Layer Security (TLS) or Tor's onion services to ensure the remote server's authenticity, that is to make it harder for someone to impersonate a forge to serve you malicious updates
- Pretty Good Privacy (PGP) to ensure the document's authenticity, that is to make it harder for someone who took control of your account/forge to serve malicious updates
How we bootstrap trust (from the ground up) for those additional layers, however, is not a simple problem. Traditional TLS setup rely on absolute trust in a pre-defined list of 3rd-party Certificate Authorities, and CAs abusing their immense power is far from unheard of. Onion services and PGP, on the other hand, require prior knowledge of authentic keys (key exchange). With the DANE protocol, we can bootstrap TLS keys from the domain name system (DNS) instead of the CA cartel. However, this is still not supported by many clients, and in any case is only as secure as DNS itself. That is, very insecure despite recent progress with DNSSEC. For a location-based system to be secure, we need a secure naming system like the GNU Name System to enable secure key exchange.
These difficulties are inherent properties of location-addressed storage, in which we describe where is a valid source of the information we're looking for. Centralized and federated systems are by definition location-addressed systems. Peer-to-peer systems, on the other hand, don't place trust in specific entities. In decentralized systems, trust is established either via cryptographic identities and signatures and/or content-addressed storage (CAS).
Signatures verify the authenticity of a document compared to a known public key. For example, when we trust the Tor project's PGP key (EF6E286DDA85EA2A4BA7DE684E2C6E8793298290), we can obtain the Tor browser (and corresponding signature) from any source, and verify the file was indeed signed by Tor developers. Content-addressed storage, in comparison, merely matches a document with a checksum, and does not provide authorship information.
So, with these building blocks in place, how do we discover new content in a decentralized system? There are typically two approaches to this problem: consensus and gossip. There may be more, but i'm not aware of them.
Consensus
Consensus is an approach in which all participating peers should agree on a single truth (a global state). They take votes following a protocol like Raft, and usually the majority wins. In a closed-off system controled by a limited number of people, a restricted set of trusted peers is allowed to vote. These peers can either be manually approved (static configuration), or be bootstrapped from a third party such as a local certificate authority controlled by the same operators.
But these traditional consensus algorithms do not work for public systems. If anyone can join the network and participate to the consensus establishment (not just a limited set of peers), then anyone may create many peers to try and take control of the consensus. This attack is often known as Sybil attack, pseudospoofing, or 51% attack.
Public systems of consensus like Bitcoin use a Proof-of-Work algorithm (PoW) to reduce the risk of a Sybil attack. Such blockchains are not determined by a simple majority vote, but rather by a vote by the majority of global computing power. While this represents a mathematical achievement, it means whoever controls the majority of computing power controls the network. This situation already happened in Bitcoin's past, and may happen again.
As we speak, the Bitcoin network already relies on a handful of giant computing pools, mostly running in China where coal-produced electricity is cheap ⁽³⁾. As time goes by, two things happen:
-
difficulty goes up so mining becomes less rewarding, and may even cost you money depending on your hardware and your source of electricity; there was a time when mining on a GPU was profitable, and even before that, mining on a CPU was profitable for quite a while
-
the blockchain grows more and more (7.5MB in 2010, 28GB in 2015, 320GB nowadays), so joining the network requires ever-growing resources
 To recap, hardware requirements go up, while economic incentives go down. What could possibly go wrong with this approach? Even worse, Bitcoin's crazy cult of raw computational power has serious ecological consequences. Bitcoin, a single application, uses more electricity than many countries. Also, all the dedicated hardware (ASIC) built for Bitcoin, will likely never be usable for anything else. As such, it appears global consensus is a deadend for decentralized systems.
To recap, hardware requirements go up, while economic incentives go down. What could possibly go wrong with this approach? Even worse, Bitcoin's crazy cult of raw computational power has serious ecological consequences. Bitcoin, a single application, uses more electricity than many countries. Also, all the dedicated hardware (ASIC) built for Bitcoin, will likely never be usable for anything else. As such, it appears global consensus is a deadend for decentralized systems.
Gossip
Gossip is a conceptual shift, in which we explicitely avoid global consensus. Instead, each peer has their own view of the network (truth), but can ask other peers for more information. Gossip is closer to how actual human interactions work: my local library may not have all books every printed, but whatever i find in there i can freely share with my friends and neighbors. ⁽⁴⁾ Identity in gossip protocols is usually powered by asymmetric cryptography (like PGP), so that all messages across the network can be signed and authenticated.
Gossip can be achieved through any channel. Usually, it involves USB keys and local area networks (LAN). But nothing prevents us from using well-known locations on the Internet to exchange gossiped information, much like a local newspaper or community center would achieve in the physical world. That's essentially what the Secure ScuttleButt (SSB) protocol is doing with its pubs, or PGP with keyservers.
In my view, gossip protocols include IPFS and Bittorrent. That's because they rely on Distributed Hash Tables (DHTs). Compared to a Bitcoin-style blockchain (where every peer needs to know about everything for consistency), In a DHT, no peer knows about everything (reducing hardware requirements to join the DHT), and consistency is ensured by content addressing (checksumming the information stored).
The database (DHT) is partitioned (divided) across many peers who each have their view of the network, but existing peers will gladly help you discover content they don't have, and ensuring authenticity of the data is not hard thanks to checksums. In this sense, i consider DHTs to be some kind of globally-consistent gossip.
It's not (yet) a widely-researched topic, but it seems IPv6 multicast could be used to make gossiping a lower-level concern (on the network layer). If you're interested in this, be sure to check out a talk called Privacy and decentralization with Multicast.
Popular self-defense against malicious activity
One may object that favorizing interaction across many networks will introduce big avenues for malicious activity. However, i would argue this does not have to be true. The same could be said of the Internet as a whole, or email in particular. But in practice, we have decades of experience (including many failures) about how to protect users from spam and malicious activities in a decentralized context.
Even protocols who initially discarded such concerns as secondary are eventually rediscovering well-known countermeasures. Some talks from the last ActivityPub conference (watch on Peertube) touch on these topics. I personally recommend a talk entitled Architectures of Robust Openness.
What about information which you published by mistake, or information which you willingly published but may cause you harm? And what about spam?
Revocation and deniability
In the first case, how do you take down a very secret piece of information you did not intend to publish? I am unaware of any way of achieving this in a decentralized manner. Key revocation processes (like with PGP) rely on good faith from other peers, who have incentives to honor your revocation certificate, as the revocated material was a public key, not a secret document.
However, even in a centralized system, there's only so much you can do following an accidental publication. If you published a password or private key, you can simply rotate it. However, if you published a secret document, it may be mirrored forever on some other machines, even if you force-pushed it out. In that sense, a forging repository is similar to a newspaper: better think twice about what you write in your article, because it will be impossible to destroy every copy once it's been distributed.

Plausible deniability addresses the second concern. In modern encrypted messengers (OTR/Signal/OMEMO), encryption keys are constantly rotated, and previous keys are shared. Authenticity of a message is proven in the present, but you cannot be held responsible for a past message, because anyone could have forged the signature by recycling your now-public private key.
While it may seem like a secondary concern, plausible deniability can be a (litterally) life-saving property in case of political dissent. That's why Veracrypt has hidden volumes. That's also why some people are now calling on mail providers to publish their previous DKIM private keys: plaintext emails would be plausibly deniable, while retaining strong authenticity for PGP-signed emails (as intended).
In decentralized public systems like software forges, i am unaware of any effort to implement plausible deniability. By instinct, i feel like plausible deniability is incompatible with authentication, which is a desired property for secure forging. However, i don't know that for sure. I'm also not sure about the need for plausibly-deniable forging, as developers are usually tracked and persecuted through other means, like mailing lists or mobile phone networks.
SPAM
Another vector of harm is spam and otherwise undesired content. It is often said that combatting spam in a decentralized environment is a harder problem. However, as previously explained, some decentralized systems have decades of experience in fighting malicious activities.
Simple techniques like rate-limiting, webs of trust (WoT), or (sometimes user-overridable) allow/deny lists can go very far to protect us from spam. However, there are techniques invented for the web and for emails which should never be reused, because they are user-hostile antipatterns: IP range bans, and 3rd party denylisting.
Banning entire IP address ranges is a common practice on the web, and the reasoning is that if you received malicious activity from more than one address in an IP range, you'd better ban the entire range, or even all addresses registered from the same country. While this may protect you from an unskilled script kiddie spamming a forum, it will prevent a whole bunch of honest users from using your service.
For example, banning Tor users from your service will do little to protect you from undesired activities. Bad actors usually have a collection of machines/addresses they can start attacks from. When that is not the case, a few dollars will get them a bunch of virtual private servers, each with a dedicated address. For a few dollars more, they'll get access to a botnet running from residential IP addresses. This means blocking entire IP ranges will only block legitimate users, but will not stop bad actors.
Renting under-the-radar residential IP addresses was already common practice years ago with people offered money or free TV services in exchange for placing a blackbox in their network. Nowadays, "smart" TVs, lightbulbs, cameras and other abominations will do the trick with even less mitigation strategies. The Internet of Things is a capitalist nightmare that hinders our security (see this talk) and destroys the environment.
The other common antipattern in fighting malicious activities is delegating access control to a third party. In the context of a webbrowser's adblocker, it makes sense to rely on denylists maintained by other persons: you may not have time to do it yourself, and if you feel like something is missing on the page, you can instantly disable the adblocker or remove specific rules. On the server side however, using a 3rd party blocklist may introduce new problems.
How can users report that they are (wrongfully) blocked from your services, if they cannot access those services in the first place to find your contact information? How can they reach you if their email server is blocked, because a long time ago someone spammed from their IP address? In the specific case of email, most shared blocklists have a procedure to get unlisted. But some other blocklists don't.
On the web, CloudFlare is well-known as a privacy-hostile actor: they will terminate TLS connections intended for your service, snooping on communications between your service and its users. Moreover, CloudFlare blocks by default any activity that comes from privacy-friendly networks like Tor, trapping users in endless CAPTCHA loops. They also block user agents they suspect to be bots, preventing legitimate scrapers indexing or archiving content.

Would you allow a private multinational corporation to stop and stripsearch anyone trying to reach your home's doorbell? Would you allow them to prevent your friends and neighbors from reaching you, because they refuse to be stripped? That's exactly what CloudFlare is doing in the digital world, and that is utterly unacceptable. All in all, Fuck CloudFlare! Yes, there's even a song about it.
So, there's nothing wrong with banning malicious actors from your network and services. But what defines a malicious actor? Who gets to decide? These are extremely political question, and delegating such power to privacy-hostile third party services is definitely not the way to go.
Existing decentralized forging solutions
Now that we have covered some of the reasons why decentralized forging is important and how to deal with malicious activities, let's take a look at projects people are actually working on.
Federated authentication
Some web forges like Gitea propose OpenID federated authentication: you can use any OpenID account to authenticate yourself against a such selfhosted forge. Compared to OAuth, OpenID does not require the service operator to list explicitely all accepted identity providers. Instead of having a predetermined list of "login with microfacegoogapple" buttons, you have a free form for your OpenID URL.
Whether you're signing up for the first time or signing in, you give your OpenID URL to the forge. You will then be redirected to the corresponding OpenID server, authenticated (if you are not yet logged in) and prompted whether you want to authenticate on the forge. If you accept, you will be redirected to the forge, who will know the OpenID server vetted for your identity.
Newer standards like OpenID Connect also feature a well-known discovery mechanism, so you don't have to use a full URL to authenticate yourself, but a simple user@server address, as we are already used to. Federated authentication can also be achieved via other protocols, such as email confirmation, IndieAuth or XMPP/Jabber (XEP 0070 or 0101).
The federated authentication approach is brilliant because it's simple and focuses on the practicality for end-users. However, it does not solve the problem of migrating projects between forges, nor does it enable you to forge from your usual tools/interfaces.
Federated forging
Federated forging relies on a federation protocol and standard vocabulary to let users cooperate across servers. That means a whole ecosystem of interoperable clients and servers can be developed to suit everyone's needs. This approach is exemplified by the ForgeFed and Salut-à-Toi projects.
ForgeFed is a forging extension for the ActivityPub federation protocol (the fediverse). It has a proof-of-concept implementation called vervis and aims to be implementable for any web forge. However, despite some interesting discussions on their forums, there seems to be limited activity implementation-wise.
Salut-à-Toi on the other hand, is an existing suite of clients for the Jabber federation (XMPP protocol). They have CLI, web, desktop and TUI frontends to do social networking on Jabber. From this base, they released support for decentralized forging in july 2018.
It's still a proof-of-concept, but it's reliable enough for the project to be selfhosted. In this context, selfhosted means that salut-à-toi is the forging software used to develop salut-à-toi itself. This all happens here.
While such features are not implemented yet, the fact that these federated forge rely on standard vocabulary would help with migration between forges, without having to use custom APIs for every forge, as is common for Github/Sourceforge/Bugzilla migrations.
As the user interactions themselves are federated, and not just authentication, folks may use their client of choice to contribute to remote projects. This means lesser concerns for color themes or accessibility on the server side, because all of these questions would be addressed on the client side. This is very important for accessibility, ensuring your needs are covered by the client software, and that a remote server cannot impact you in negative ways.
If your email client is hard for you to use, or otherwise unpleasant, you may use any email-compatible client that better suits your needs. With selfhosted, centralized forges, where the client interface is tightly-coupled to the server, every forge server needs to take extra steps to please everyone. Every forge you join to contribute to a project can make your user experience miserable. Imagine if you had to use a different user interface for every different server you're sending emails to?!
Federated forging, despite being in early stages, is an interesting approach. Let servers provide functions tailored to the project owners, and clients provide usability on your own terms.
Gossip
An early attempt based on Bittorrent's DHT was Gittorrent. Another one was git-remote-ipfs, based on IPFS instead. The project is now unmaintained, but it can be replicated with a simple IPFS HTTP gateway. While these proof-of-concept systems did not support tickets and patches, they were inspirational for more modern attempts like git-ssb and radicle.
git-ssb implements forging capabilities on top of the Secure ScuttleButt (SSB) gossip protocol. SSB was designed for an offline-first usage, with local wifi hotspots or sharing USB keys. This makes the system very resilient, though worldwide cooperation between strangers is an afterthought.
radicle is another project, with a homegrown gossip protocol explicitely designed for forging. The project is still in early stages, but there's growing interest around it. They have a dedicated development team and a roadmap, and they claim Monadic (their employer) will not own any of the Radicle ecosystem, but rather contribute to it under the guidance of a non-profit foundation.
While radicle's funding isn't clear from my perspective, and therefore triggers my cryptostartup vaporware bullshit-o-meter, what i could read from their forums and hear from their presentations gave me confidence they really intend to build a community/standards-driven project for the improvement of the ecosystem. Also worth noting, their jobs page claims decision-making is a horizontal process, and all of their employees are paid the same. Even more exciting, radicle uses strong cryptography to sign commits in a very integrated and user-friendly way. That's a strong advantage over most systems in which signatures are optional and delegated to third-party tooling which can be hard to setup.
Although these peer-to-peer forges are less polished for day-to-day use, they helped pave the way for research into decentralized forging by showing that git and other decentralized version control systems (DVCS) play well with content-addressed storage (given that a commit is an actual checksum) and peer-to-peer networks.
Consensus
Apart from sketchy Silicon Valley startups, nobody is attempting to build consensus-based forging solutions, because of the many problems i explained before (with Bitcoin). When i started drafting this article, Radicle seemed keen on using blockchains and global consensus. But since then, they've reevaluated their decision, though not for any of the reasons i proposed, but rather because of legal problems due to blockchain poisoning. Nowadays, Radicle intends to use Ethereum, but only as a complement (not replacement) to their gossip protocol.
Not covered here
Many more projects over the years have experimented with storing forging interactions (metadata like bugs and pull requests) as well-known files within the repository itself. Some of them are specific to git: git-dit, ticgit, git-bug, git-issue. Others intend to be used with any versioning system (DVCS-agnostic): artemis, bugs-everywhere, dits, sit.
I will not go into more details about them, because these systems only worry about the semantics of forging (vocabulary), but do not emphasize how to publicize changes. For example, these tools would be great for a single team having access to a common repository to update tickets in an offline-first setting, then merging them on the shared remote when they're back online. But they do not address cooperation with strangers, unless you give anyone permission to publish a new branch to your remote, which is probably a terrible idea. However, that's just my personal, uninformed opinion: if you have counter-arguments about how in-band storage of forging interactions could be used for real-world cooperation with strangers, i'd be glad to hear about it!
Lastly, i didn't mention Fossil SCM because i'm not familiar with it, and from reading the docs, i'm very confused about how it approaches cooperation with strangers. It appears forging interactions are stored within the repository itself, but then does that mean that Fossil pulls every interaction it hears about from strangers? Or is Fossil only intended for use in a closed team, as this page seems to indicate? Let me know if you have interesting articles to learn more about Fossil.
With interoperability, please
After this brief review of the existing landscape of decentralized forging, i would like to argue for interoperability. If you're not familiar with this concept, it's a key concern for accessibility/usability of both physical and digital systems: interoperability is the property when two systems addressing the same usecases can be used interchangeably. For example, a broken lightbulb can be replaced by any lightbulb following the same socket/voltage standards, no matter how it works internally to produce light.
In fact, interoperability is the default state of things throughout nature. To make fire, you can build any sort of wood that burns. If your window is broken and you don't have any glass at hand, you can replace it with any material that will prevent air flowing through. Interoperability is a very political topic, and a key concern to prevent the emergence of monopolies. If you'd like to know more about it, i strongly recommend a talk called We used to have cake, now we've barely got icing.
So while these approaches of decentralized forging we've talked about are very different in some regards, there is no technical reason why they could not play well together and inteoperate consistently. As a proof of concept, git-issue we've mentioned in the previous section can actually synchronise issues contained within the repository with Github and Gitlab repositories. It could as well synchronise with any selfhosted forge (federated or not), or even gossip them to git-ssb or radicle.
The difference between federated and p2p systems is big, but hybrid p2p/federated systems have a lot of value. If we develop open standards, there is no technical barrier for a peer-to-peer forge to synchronise with a federated web/XMPP forge. It may be hard to wrap one's head around, and may require more for implementation, but it's entirely possible. Likewise, a federated forge could federate both via ForgeFed, and via XMPP. And it could itself be a peer in a peer-to-peer forge, so that pull requests submitted on Radicle may automatically appear on your web forge.
Not all forges have to understand each other. But it's important that we at least try, because the current fragmentation across tiny different ecosystems is hostile to new contributions from people who are used to different workflows and interfaces.
Beyond cooperation, interoperability would also ease backups, forks and migrations. Migrating your whole project from a forge to another would only take a single, unprivileged action. When forking a project, you would have a choice whether to inherit all of its issues and pull requests or not. So if you're working on a single patch, you would discard it. But in case you want to take over an abandoned project, you would inherit all of the project's history and discussions, not just the commits.
You may have noticed i did not mention the email workflow in this section about interoperability. That's because email bugtracking and patching is far from being standardized. Many cncerns expressed in this article would equally apply to email forging. But to be honest, i'm not knowledgeable enough about email-based forging to provide a good insight on this topic. I'm hoping people from the sourcehut forge community and other git email wizards can find inspiration in this call to decentralized forging, come around the table, and figure out clever ways to integrate into a broader ecosystem.
Code signing and nomadic identity
How to ensure authenticity of interactions across different networks? Code signing in forging usually uses PGP keys and signatures to authenticate commits and refs. In most cases, it is considered a DVCS-level concern and is left untouched by the forge, except maybe to display a symbol for valid signature alongside a commit. While we may choose to trust the forge regarding commit signatures, we may also verify these on our end. The tooling for verifying signatures is lacking, although there is recent progress with the GNU Guix project releasing the amazing guix git authenticate command for bootstrapping a secure software supply chain.
However, forging interactions such as issues are typically unsigned, and cannot be verified. In systems like ActivityPub and radicle, these interactions are signed, but with varying levels of reliability. While radicle has strong security guarantees because every client owns their keys, email/ActivityPub lets the server perform signatures for the users: a compromised server could compromise a lot of users and therefore such signatures are unreliable from a security perspective. We could take this into consideration when developing forging protocols, and ensure we can embed signatures (like PGP) into forging intereactions such as tickets.
For interoperability concerns, each forge could implement different security levels, and let maintainers choose the security properties they expect for external contributions, depending on their practical security needs. A funny IRC bot may choose to emphasize low-barrier contribution across many forges over security, while a distribution may enforce stricter security guidelines, allowing contributions only from a trusted webforge and PGP-signed emails. In any case, we need more user-friendly tools for making and verifying signatures.
Another concern is how to deal with migrations. If my personal account is migrated across servers, or i'm rotating/changing keys, how to let others know about it in a secure manner? In the federated world, this concern has been addressed by the ZOT protocol, which as initially developed for Hubzilla's nomadic identity system. ZOT lets you take your content and your friends to a new server at any given moment.
This is achieved by adding a crypto-identity layer around server-based identity (user@server). This crypto-identity corresponding to a keypair (think PGP) is bootstrapped in a TOFU manner (Trust On First Use) when federating with a remote user on a server that supports the ZOT protocol. The server will give back the information you requested, and let you know the nomadic public key for the corresponding user, and other identities signed with this keypair.
For example, let's imagine for a second that tildegit.org and framagit.org both supported the ZOT protocol and some form of federated forging. My ZOT tooling would generate a keypair, that would advertise my accounts on both forges. Whenever i push changes to a repository, these changes would be pushed to the two servers simultaneously. When someone clones one of my projects, their ZOT-enabled client would save my nomadic identity somewhere. This way, if one of the two server ever closes, the client would immediately know to try and find my project on the other forge.
In practice, there would be a lot more subtlety to represent actual mapping between projects (mirrors), and to map additional keypairs on p2p networks (such as radicle) to a single identity. However, a nomadic identity system doesn't have to be much more complex than that.
The more interesting implementation concern is how to store, update and retrieve information about a nomadic identity. With the current ZOT implementations, identities are stored as signed JSON blobs, that you retrieve opportunistically from a remote server. However, that means if all of your declared servers are offline (for instance, if there's only one of those) one cannot automatically discover updates to your nomadic identity (new forges to find your projects).
I believe a crypto-secure, decentralized naming system such as GNS or IPNS would greatly benefit the nomadic identity experience. DNS could also be used here, but as explained before, DNS is highly vulnerable to determined attackers. Introducing DNS as discovery mechanism for nomadic identities would weaken the whole system, and make it much harder to get rid of in the future (for backwards-compatibility).
With GNS/IPNS (or any other equivalent system), people would only need to advertise their public key on every forge, and the nomadic identity mapping would be fetched in a secure manner. Considering GNS is in fact a signed and encrypted peer-to-peer key-value store itself, we could use GNS itself to store nomadic identity information (using well-known keys). IPNS, on the other hand, only contains an updatable pointer to an IPFS content-addressed directory. In this case, we would use well-known files within the target directory.
So, migration and failover across forges should also be feasible, despite other challenges not presented here, such as how to ensure consistency across decentralized mirrors, and what to do in case of conflicts.
Social recovery and backup mechanisms
Introducing strong cryptographic measures as proposed in the previous sections introduces new challenges, in particular about account recovery mechanisms in case of lost key/password. In the case of federated forges, for instance, the server does not have access to users' private keys and therefore cannot help users recover their account.
That's a good thing, because it means a compromised server cannot compromise its users, whether willingly or not. However, this is counterintuitive for most users who are used to password reset forms, and are (understandably) pissed to loose many things simply because they forgot a password.
To workaround this issue, many encrypted services providers provide recovery codes that you should write down and store safely, enabling you to regenerate your private key and/or reset your password in the future. However, where you store this highly-secret recovery code can either be compromised (eg. physical intrusion in your home), and in any case, loosing access to this recovery code will leave you helpless.
That's why the hosting cooperative Riseup also enables account recovery via email, but whatever the recovery mechanism you use, your entire mailbox will be deleted. In this case, the recovery mechanism will let you recover your identity, but will not help compromise you and other people by revealing your secrets to a potential attacker.
Another approach to this problem is Shamir's secret sharing scheme (ssss), which divides a secret in several parts, a certain number of which have to be reunited to recover the secret. These smaller parts of the secrets can then be encrypted for people you trust, and kept safely with them.
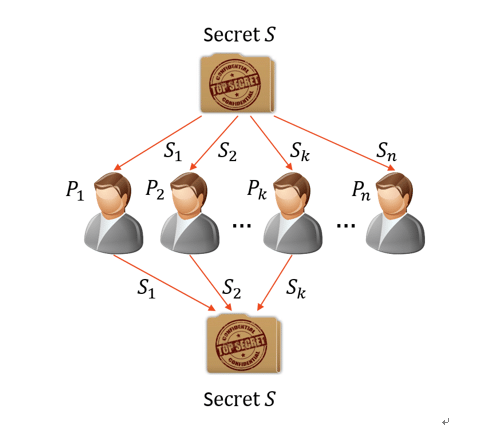
Shamir's approach is interesting and can be successful because it considers the problem of account recovery from a trust perspective: how can we empower users to delegate trust to people of their choice, and not to a single third-party service which could compromise them. Shamir's algorithm also successfuly accounts for a trusted party becoming unavailable or uncooperative, by not requiring that all parties agree to recover the secret (but a configurable fraction of them). In short, it allows the employment of not fully trusted people.
In this area also, we need research and work on better tooling focused on user experience. Conceiving availability/recovery issues as social problems opens the door to solving many problems, not just for end-users in a federated/peer-to-peer setup. For instance, tooling that enables sysadmins to perform/receive backups in a socially aware manner like Yunohost does does a great deal to improve reliability of services for resources-constrained sysadmins.
Conclusion
Decentralized forging is in my view the top priority for free-software in the coming decade. The Internet and free-software have a symbiotic relationship where one cannot exist without the other. They are two facets of the same software supply chain, and any harm done on one side will have negative consequences on the other. Both are under relentless attack by tyrants (including pretend-democracies like France or the USA) and multinational corporations (like Microsoft and Google). Developing decentralized forging tooling is the only way to save free software and the Internet, and may even lower the barrier to contribution for smaller community projects.
Of course, decentralized forging will not save us from the rise of fascism in the physical and digital world. People will have to stand up to their oppressors. Companies and State infrastructure designed to destroy nature and make people's lives miserable will have to burn. And we have to start developing right now the world we want to see for the future.
« We are not in the least afraid of ruins. We are going to inherit the earth; there is not the slightest doubt about that. The bourgeoisie might blast and ruin its own world before it leaves the stage of history. We carry a new world here, in our hearts. That world is growing in this minute. » -- Buenaventura Durruti
⁽¹⁾ Microsoft has tried to buy themselves a free-software friendly public image in the past years. This obvious openwashing process has consisted in bringing free software to their closed platform (eg. Windows Subsystem for Linux), and open-sourcing a few projects that they could not monetize (eg. VSCode), while packaging them with spyware (telemetry). Furthermore, Microsoft has been known for decades to cooperate with nation States and the military industrial complex.
⁽²⁾ Catalonia has a long history of oppression and repression by the spanish State. Microsoft is just the latest technological aid for that aim, just like Hitler and Mussolini in their time provided weapons to support Franco's coup (in 1936), and crush the democratically-elected social front, then the social revolution.
⁽³⁾ Cheap electricity on the other side of the world is the only reason we have cheap hardware. It takes considerably more energy to produce a low-powered device like a Raspberry, than to keep an old computer running for decades, but the economical incentives are not aligned.
⁽⁴⁾ In many countries, sharing copyrighted material in a restricted circle is legal as long as you obtained the material in a legal manner. For example, copying a book or DVD obtained from a library is legal. Throughout the french colonial empire, this is defined by the right to private copy (copie privée).